2026/6/20 12:23:54
网站建设
项目流程
做网站的公司给出个证明,中国进入一级战备2023,网站建设制作免费咨询,装修效果图实景案例文章目录网关作用工作原理predicates 断言1. 写法2. 断言机制3. 自定义断言filters 过滤器1. RewritePath GatewayFilter Factory#xff08;路径重写#xff09;2. 默认 filter3. Global Filter全局过滤器4. 自定义过滤器跨域网关作用
官方文档#xff1a;https://docs.sp…文章目录网关作用工作原理predicates 断言1. 写法2. 断言机制3. 自定义断言filters 过滤器1. RewritePath GatewayFilter Factory路径重写2. 默认 filter3. Global Filter全局过滤器4. 自定义过滤器跨域网关作用官方文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/index.htmlSpring Cloud Gateway:Server WebFlux ——spring-cloud-starter-gatewayServer MVC —— spring-cloud-starter-gateway-mvc性能较差工作原理spring:profiles:active:devapplication:name:easylive-cloud-gatewaycloud:gateway:routes:#视频模块-id:videouri:lb://easylive-cloud-webpredicates:-Path/web/**filters:-StripPrefix1#互动服务-id:interacturi:lb://easylive-cloud-interactpredicates:-Path/interact/**filters:-StripPrefix1spring-cloud-gateway下的配置id服务唯一标识uri服务路由地址lb表示负载均衡predicates断言判断什么时候路由到该服务filters过滤条件order顺序值越小优先级越高predicates 断言1. 写法文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/spring-cloud-gateway-server-webflux/configuring-route-predicate-factories-and-filter-factories.html短写法长写法2. 断言机制文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/spring-cloud-gateway-server-webflux/request-predicates-factories.html#path-route-predicate-factory3. 自定义断言可以仿照 QueryRoutePredicateFactory 编写一个自定义断言配置。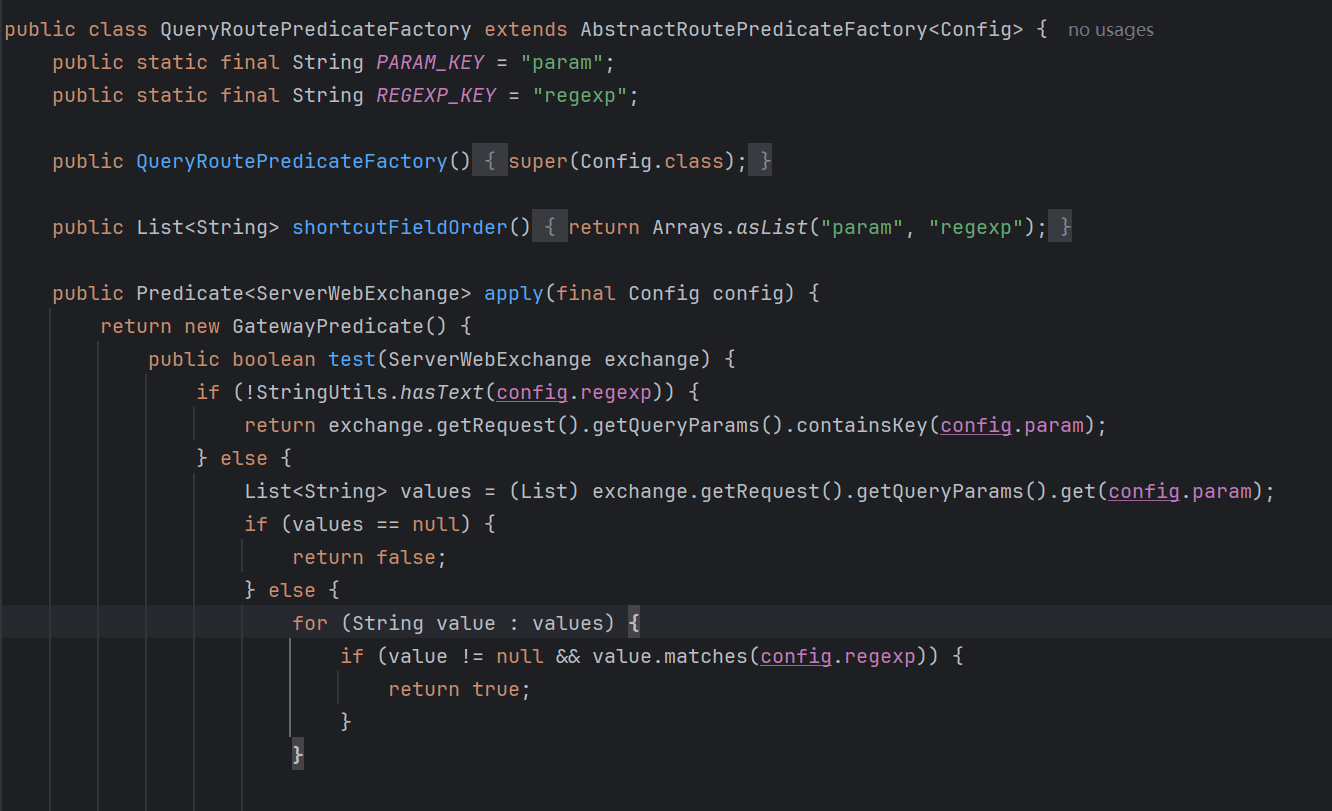自定义断言类的类名中 RoutePredicateFactory 之前就是就是配置文件中要写入的断言名 name 。filters 过滤器官方文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/spring-cloud-gateway-server-webflux/gatewayfilter-factories.html1. RewritePath GatewayFilter Factory路径重写RewritePath GatewayFilter Factory 路径重写 filter2. 默认 filter对所有路径均有效的过滤器。官方文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/spring-cloud-gateway-server-webflux/gatewayfilter-factories/default-filters.html3. Global Filter全局过滤器官方文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/spring-cloud-gateway-server-webflux/global-filters.htmlComponentSlf4jpublicclassGatewayGlobalRequestFilterimplementsGlobalFilter,Ordered{OverridepublicMonoVoidfilter(ServerWebExchangeexchange,GatewayFilterChainchain){// 获取请求的URIStringrawpathexchange.getRequest().getURI().getRawPath();// 判断请求的URI是否是内部APIif(rawpath.indexOf(Constants.INNER_API_PREFIX)!-1){thrownewBusinessException(ResponseCodeEnum.CODE_404);}log.info(这个是全局过滤器, {},rawpath);// 继续执行下一个过滤器returnchain.filter(exchange);}OverridepublicintgetOrder(){// 设置过滤器的优先级,数字越小优先级越高return0;}}4. 自定义过滤器仿照实现 GatewayFilterFactory 接口的某个 FilterFactory 实现。跨域跨域Cross-Origin Resource Sharing简称CORS是一种安全策略用于限制一个域的网页如何与另一个域的资源进行交互。这是浏览器实现的同源策略Same-Origin Policy的一部分旨在防止恶意网站通过一个域的网页访问另一个域的敏感数据。由于浏览器实施的同源策略Same Origin Policy这是一种基本的安全协议它确保了浏览器的稳定运行。没有同源策略浏览器的许多功能可能无法正常工作。整个Web体系建立在同源策略之上浏览器是这一策略的具体实现。该策略禁止来自不同域的JavaScript脚本与另一个域的资源进行交互。所谓同源指的是两个页面必须具有相同的协议protocol、域名host和端口号port。请求是能正常的发出去的后端也正常的响应了浏览器是把响应给拦截了所以会出现has been blocked by CORS policy: Response to preflight request does not pass access control check单体项目解决跨域1在 Controller 上添加CrossOrigin注解。2编写 CrossFilter。微服务解决跨域微服务场景下如果要对每一个服务单独编写跨域逻辑比较繁琐。Gateway 网关对接前端入口由 Gateway 处理跨域所有请求经过网关网关处理后所有的响应都允许跨域。官方文档https://docs.spring.io/spring-cloud-gateway/reference/4.3/spring-cloud-gateway-server-webflux/cors-configuration.html服务端通过在响应头中添加某些信息告知浏览器哪些来源可以访问浏览器就不再拦截响应。